
DocKit 导入导出 - 跨 NoSQL 数据库无缝迁移数据
在 NoSQL 数据库之间迁移数据是日常但繁琐的工作。集群迁移、测试数据填充、升级前备份——这些都需要一种可靠的方式导入和导出数据,而不需要编写自定义脚本或与云控制台博弈。DocKit 的导入/导出功能将这种能力直接内置在桌面客户端中,数据不会离开您的机器。
DocKit 支持哪些格式
DocKit 的导入/导出引擎支持三种广泛使用的数据格式:
| 格式 | 导入 | 导出 | 最适合 |
|---|---|---|---|
| JSON | ✅ | ✅ | 人类可读、完整保真度的数据 |
| CSV | ✅ | ✅ | 电子表格工作流、扁平数据 |
| JSONL | ✅ | ✅ | 大规模 ES/OpenSearch 迁移 |
JSON 保留嵌套对象、数组和所有原生数据类型。它是在 NoSQL 数据库之间往返传输数据最可靠的格式。
CSV 非常适合需要在电子表格中打开、与非工程师共享或导入分析工具的扁平数据。DocKit 在导入时自动处理列映射和类型转换。
JSONL 格式每行一个 JSON 对象,遵循原生 Elasticsearch _bulk API 结构 — 每行在操作/元数据 JSON 对象和源 JSON 对象之间交替。这种格式是将大量数据直接加载到 Elasticsearch 或 OpenSearch 的最快方式。
如何从 Elasticsearch / OpenSearch / DynamoDB 导出数据
在 DocKit 中导出索引或表是一个简单的过程:
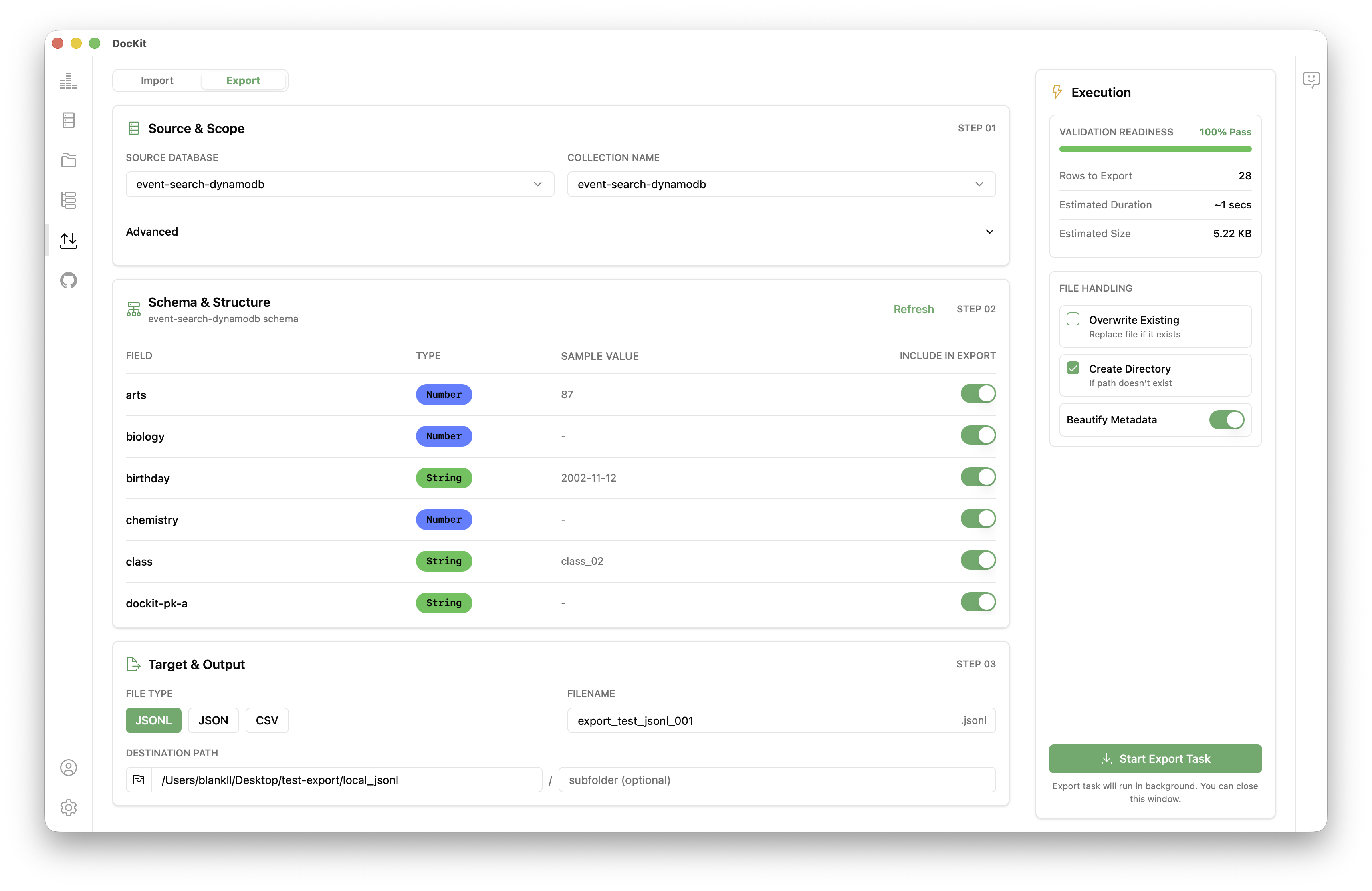
- 打开 DocKit 并连接到您的 Elasticsearch、OpenSearch 或 DynamoDB 实例。如需帮助,请参阅连接指南。
- 在左侧边栏点击导入/导出图标打开导入/导出面板,选择导出。
- 选择源数据库和集合名称作为要导出的目标数据。
- 选择输出格式:JSON、CSV 或 JSONL 格式。
- 在本地文件系统上选择输出路径。
- 可选地应用查询过滤器(Elasticsearch / OpenSearch)或过滤器表达式(DynamoDB)以仅导出匹配的子集。
- 点击导出。DocKit 流式传输数据并写入磁盘。进度条显示已导出的文档数量。
提示:
- 对于大型 Elasticsearch / OpenSearch 索引和 DynamoDB 表,使用 JSONL 格式 — DocKit 内部使用 scroll API,即使是非常大的索引也能可靠导出,不会触及内存限制。
- 导出的 JSON 保留原生属性类型(Elasticsearch 字段类型和 DynamoDB 类型如
S、N、BOOL、L、M),数据可以准确地往返传输。
如何将数据导入 Elasticsearch / OpenSearch / DynamoDB
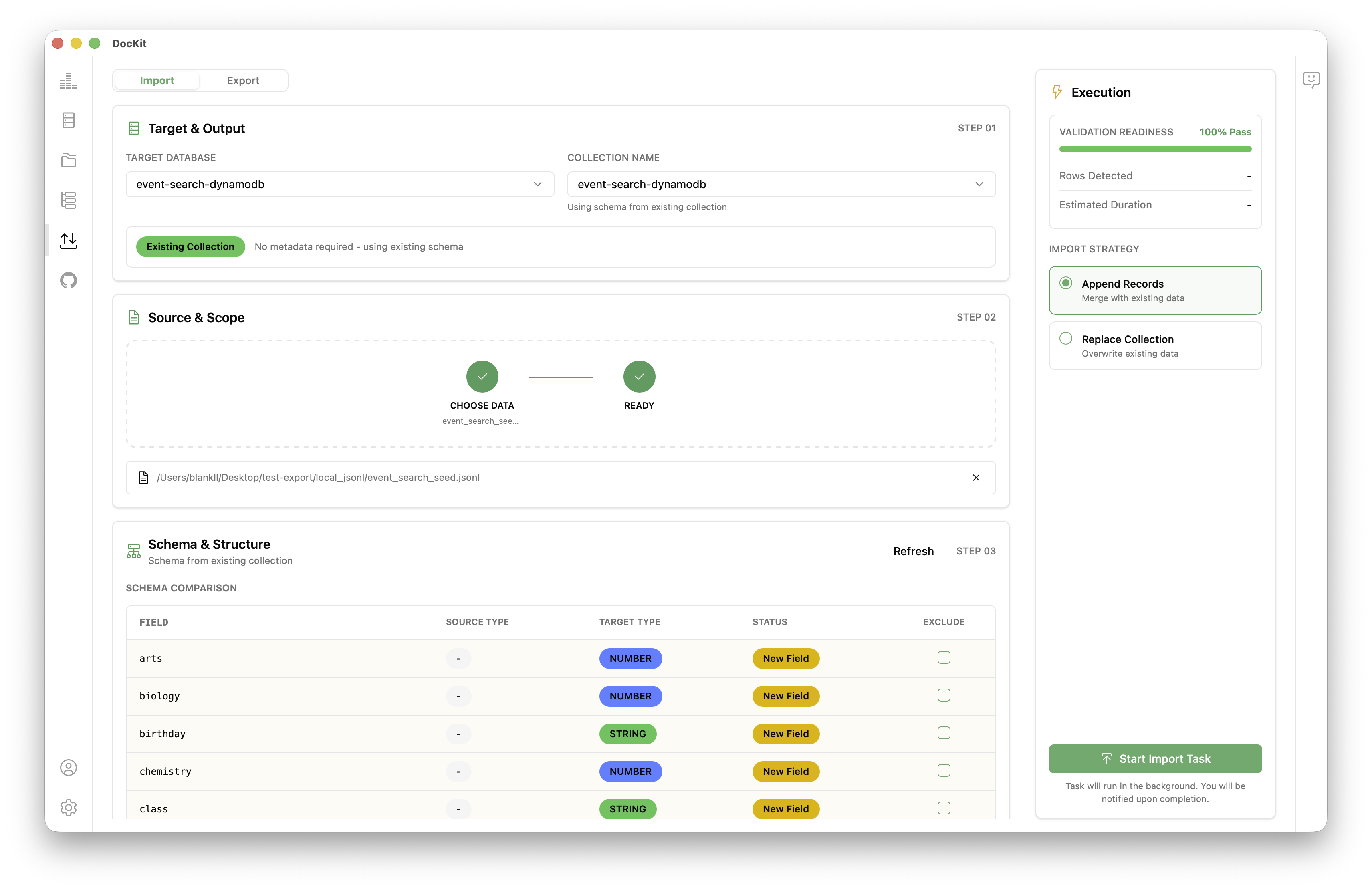
- 打开 DocKit 并连接到您的 Elasticsearch、OpenSearch 或 DynamoDB 实例。如需帮助,请参阅连接指南。
- 在左侧边栏点击导入/导出图标打开导入/导出面板,选择导入。
- 选择目标数据库和集合名称作为导入目标。
- 选择文件系统上的源文件。支持格式:Elasticsearch / OpenSearch 支持 JSON、CSV 或 JSONL;DynamoDB 支持 JSON 或 CSV。
- DocKit 自动检测文件格式。对于 CSV 文件,列映射对话框允许您将列映射到字段或属性名称和类型。
- 点击导入。DocKit 使用
_bulkAPI(Elasticsearch / OpenSearch)或BatchWriteItem(DynamoDB)并行发送数据,遵守速率限制。实时进度指示器显示已导入的文档数量和任何错误。
处理导入错误:
- DocKit 将任何失败的项目(包括其主键和错误原因)记录到导入文件旁边的错误日志文件中。
- 您可以通过直接导入错误日志文件来重试失败的项目 — DocKit 识别其格式。
DocKit 导入/导出与其他工具的比较
| 工具 | Elasticsearch | DynamoDB | GUI | 免费 |
|---|---|---|---|---|
| DocKit | ✅ | ✅ | ✅ | ✅ |
| elasticdump | ✅ | ❌ | ❌ | ✅ |
| AWS DMS | ✅ | ✅ | ✅ | ❌ |
| AWS 控制台 | ❌ | 有限 | ✅ | ✅ |
| 自定义脚本 | ✅ | ✅ | ❌ | ✅ |
DocKit 的优势在于多数据库支持、图形界面和零成本的组合。您不需要为 elasticdump 安装 Node.js,配置 AWS 数据库迁移服务,或编写和维护自定义代码。
开始使用
常见使用场景
现代开发团队在多种环境中工作:本地开发、预发布、预生产和生产环境。保持这些环境中数据的一致性,或将生产数据的代表性快照移动到较低环境中进行测试,是一项频繁且痛苦的任务。导入/导出必不可少的常见场景:
- 集群迁移:从 Elasticsearch 7 迁移到 Elasticsearch 8,或从自托管集群迁移到 Amazon OpenSearch Service 等托管云产品。
- 测试数据填充:在 QA 冲刺前用真实数据填充预发布索引或 DynamoDB 表。
- 升级前备份:在运行有风险的架构更改前导出完整的索引或表快照。
- 跨区域复制:用现有数据集引导新区域。
- 数据共享:以 JSON 或 CSV 等标准格式将数据集交给同事或客户。
在集群之间迁移
导入/导出最常见的使用场景是集群迁移。例如,从 Elasticsearch 7 升级到 Elasticsearch 8 而不进行就地滚动升级:
- 以 JSONL 格式从旧集群导出所有索引。
- 在 Elasticsearch 8 集群上使用所需的映射创建新索引。
- 将导出的文件导入新集群。
- 验证文档数量并抽查记录。
- 将应用程序流量切换到新集群。
填充测试数据
QA 团队经常需要在预发布环境中使用真实数据。使用 DocKit:
- 导出生产数据的样本(使用查询过滤器限制为非 PII 记录或匿名数据)。
- 在 QA 冲刺前将其导入到预发布索引或 DynamoDB 表中。
- 在每个发布周期前重新填充。
升级前备份
在任何有风险的操作前 — 映射更改、索引重构、主要版本升级 — 导出完整快照:
- 将受影响的索引/表导出为 JSON。
- 将导出文件存储在安全位置(S3、Git LFS 等)。
- 继续操作。如果出现问题,导入备份以恢复。
与同事共享数据
将小型数据集导出为 JSON 或 CSV,并通过电子邮件、Slack 或您首选的渠道共享。接收者可以在几秒钟内将其导入到自己的 DocKit 实例中。
相关资源
- DocKit 完整功能概览 - 支持 Elasticsearch、OpenSearch、DynamoDB
- Elasticsearch GUI 客户端 - 查询编辑器、集群管理详情
- DynamoDB GUI 客户端 - PartiQL 编辑器、可视化查询构建器详情
- GitHub 仓库 - 源代码和问题